What Should I Eat
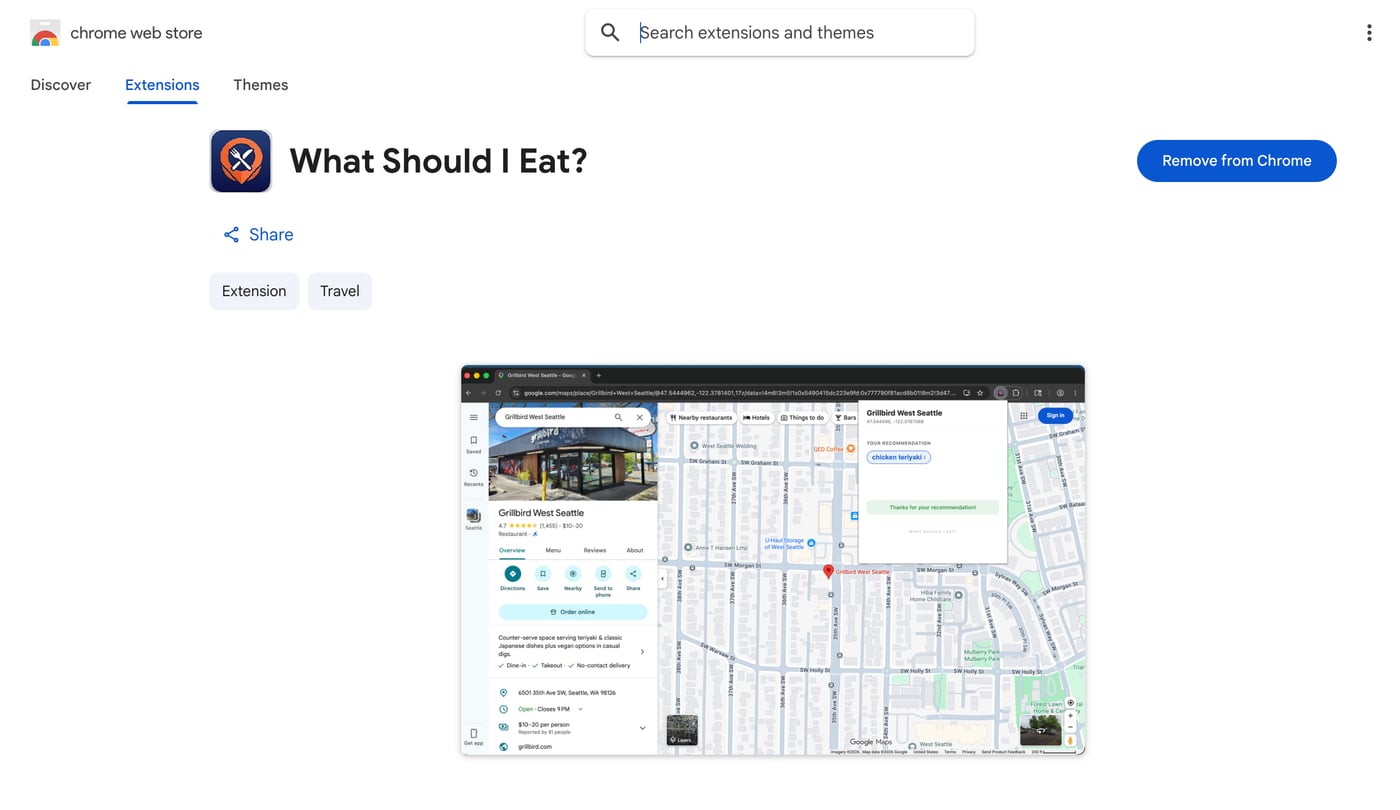
I didn’t know of any apps out there that crowdsource what the best dish at a restaurant is or a ranking of the best dishes. I’ve also never published browser plugins, I was interested in how that works. So I made this plugin.
This v1 version is for Chrome and Firefox (as of writing the draft of this blog post only the Chrome version is published).
This will probably be more useful as an android/ios app, so I’ll get around to that, but I figured I could fill in some details here about how it works and my workflow in building this.
UX
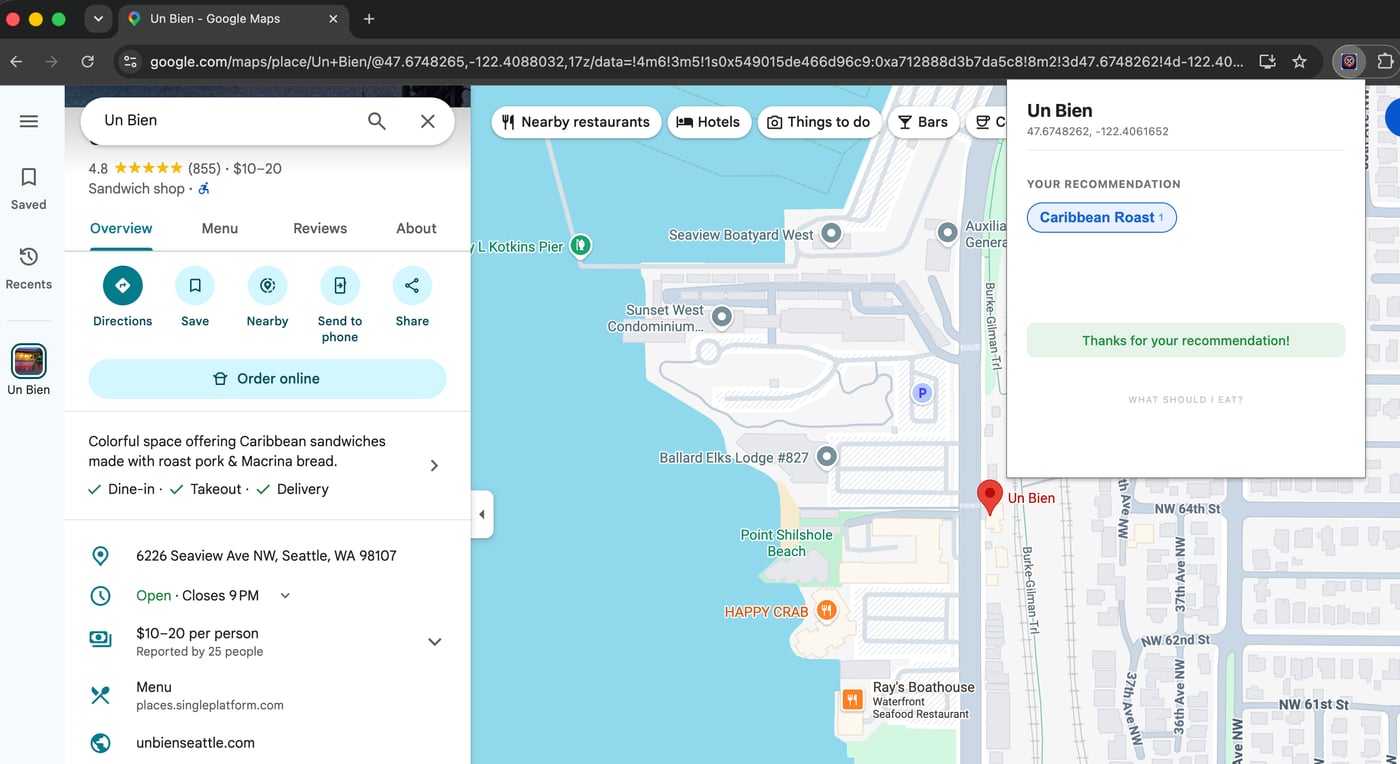
Very simple, v1 only works in Google Maps, you select a restaurant on the map, click the plugin. If the restaurant has never been clicked before, we add it automatically, then you can input what you think the best dish is. If the restaurant has been clicked before, you will see other people’s votes and you can either enter something new or click one of the dishes displayed. The UI uses a “pill cloud” where the text size grows based on how many votes a dish has, so the heavy hitters bubble up visually.
There’s no authentication, no validation on dishes entered. This was partly to keep things simple, but it’s also a feature: there is zero friction to contribute. You don’t have to sign up for yet another service just to say the lasagna is good. Yeah, you can get duplicates. Yeah, users can clear their local data and vote multiple times on a dish.
But, I don’t want to deal with data privacy, plugin approvals, etc. So I chose to make it super simple and basic.
Technical decisions
I had a tough time figuring out how exactly to manage restaurant entries. I want this to work in more than just google maps in the future, so I decided against using a google place id. Relying on Google’s IDs also makes you a bit of a hostage—if they change their internal ID system or you want to support Apple Maps or Yelp later, you’re starting from scratch.
Ultimately, I landed on using GPS coordinates. GPS coordinates will work well for mobile app functionality later, so that’s a plus. And I create a hash/uuid based on those gps coordinates, and these are deterministic based on the coordinates, so it’s easier to lookup in our single table dynamodb design. I’m also using Geohashing to bucket restaurants into ~5km squares (5-character prefixes). This lets the API query the database for just the nearby “bucket” instead of scanning the whole table, which keeps the DynamoDB costs at basically zero. Once I have the nearby results, I use the Haversine formula to calculate the exact distance in meters and sort them. (Here’s where I should note, I had/have no idea what the Haversine formula is, that’s what the LLM came up with)
To handle the “clustering” problem and GPS drift, I round the coordinates to 3 decimal places before hashing. This gives us about 110 meters of “fuzzy” snapping. It means even if you’re standing on the other side of the restaurant, it should still resolve to the same ID. It’s a little worse for locations where a lot of restaurants cluster close to each other in a tiny footprint, but it’s a trade-off I’m willing to make for platform agnosticism. In the future, I’ll add a way to select a specific restaurant if they’re clustered. At some point I’ll also have to think of a way to rename restaurants for when spots close and re-open as something new too.
Infrastructure
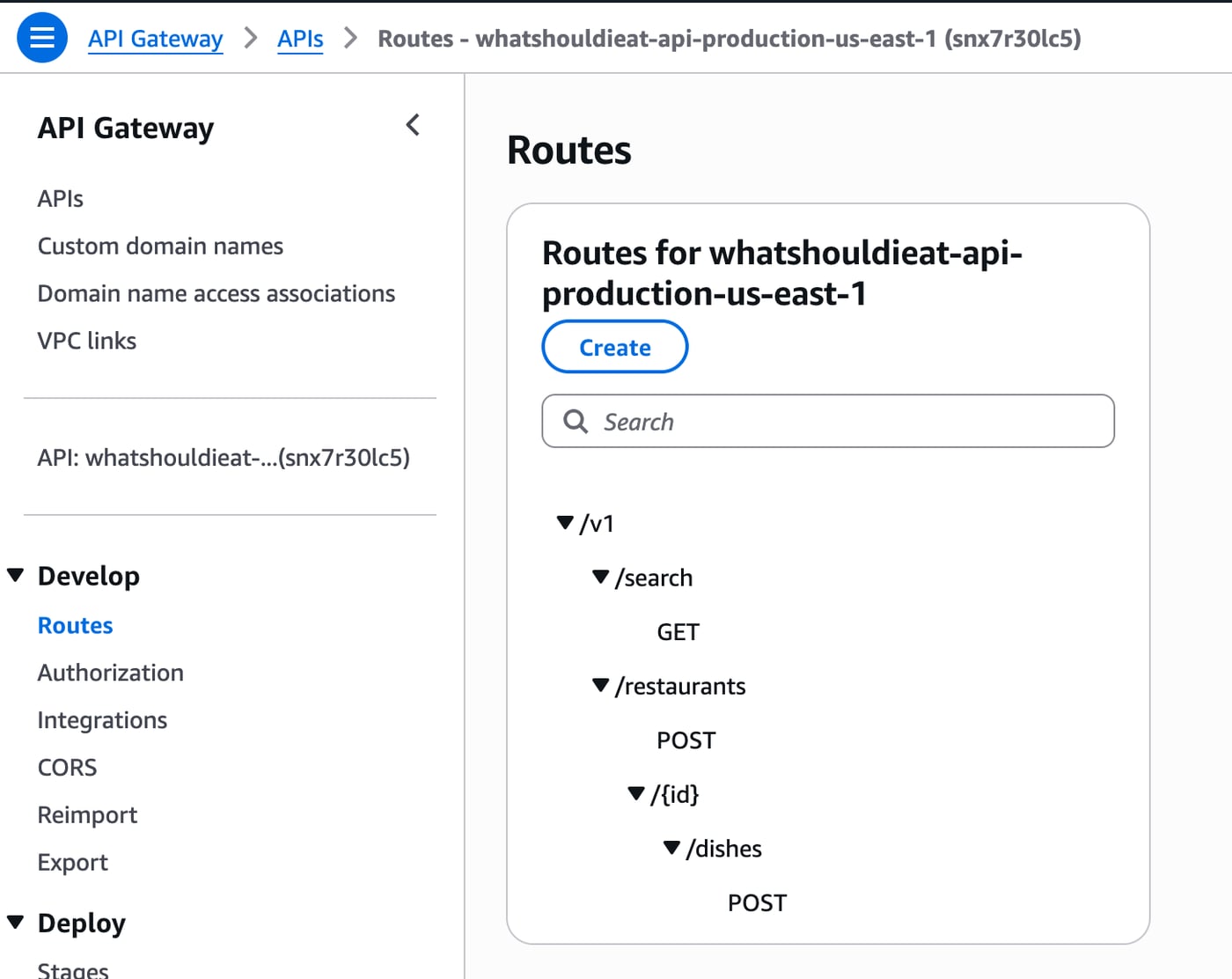
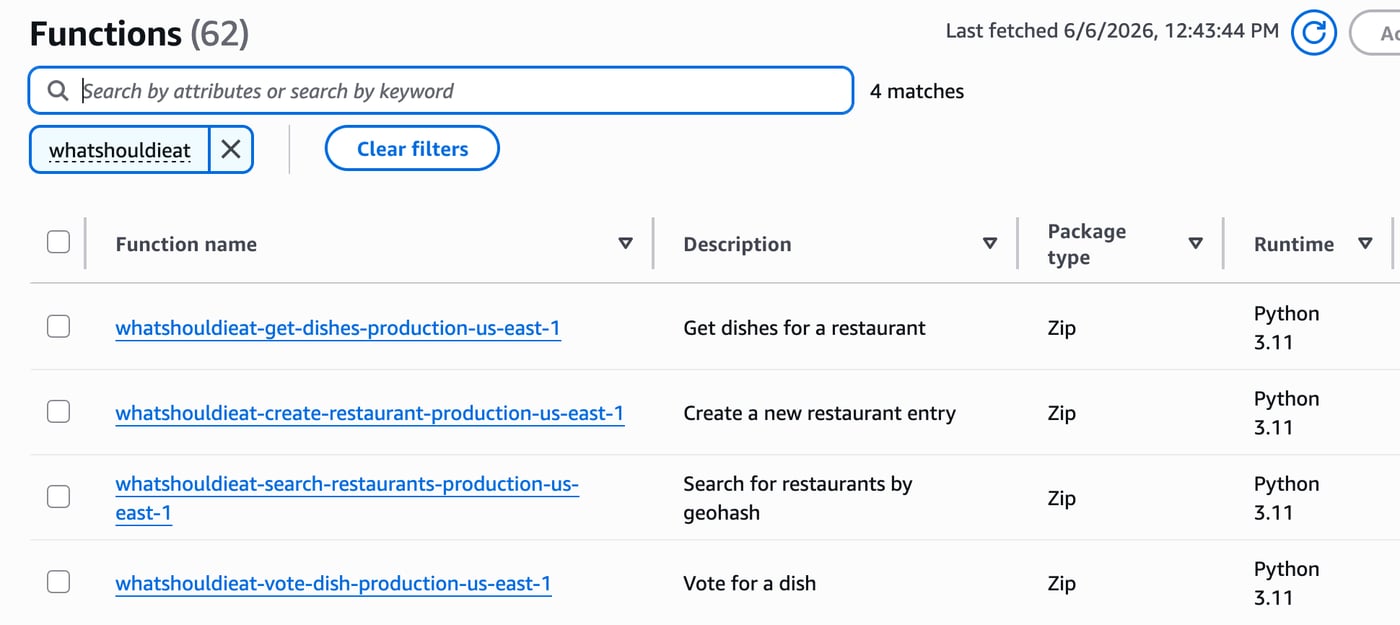
The backend is also pretty simple. It’s all in AWS running as a serverless api. All compute is in AWS Lambda, Apigw handles requests, Dynamodb for the datastore. There’s no authentication, no user accounts, it’s a really simple API. It will scale up automatically to a point and it’s pretty much free to run.
Cost to run
Well, there are very few people using this right now, so currently it’s free (besides the hosted zone, but I run multiple things off of that and it’s only $.50 a month). If this thing even gets to the point of costing me money I’d consider it pretty successful. Once it rolls over from the free tier on my stack, it will scale linearly with the number of users.
Monetization
There’s no monetization and I’d only consider monetizing this if my costs exceed my appetite. If it costs me $100+ a month, I’d try to find a simple, non-intrusive way to monetize to cover my costs. Right now, I don’t see that being in the cards so it’s not really a concern.
How I built it
I wrote almost zero code for this personally, I had an LLM do most of it. Gemini, Claude, ChatGPT all had a hand. I think this one was mostly Gemini (which at the time of writing this, June 2026, I’d say it’s the worst tool of the bunch). I don’t stay completely hands off and vibe code, I give guidance, gate the llm at certain points, manually run certain verification steps/tools. It feels more like having a conversation with a Jr Engineer who is eager to please.
I start by explaining what I want to build and telling the LLM to help me build an AGENTS/CLAUDE/GEMINI markdown file. This part usually takes anywhere from 1 to 5 prompts. I’ll also read the markdown file myself a couple times and this is where I might manually make some tweaks.
Once the markdown file is completed, I’ll discuss architecture and code patterns that I want to see. I pulled in some reference architecture/projects as well as my terraform modules for the LLM to review. After 3-5 prompts, we’ll usually reach some alignment. When I feel like it’s “good enough” I tell the LLM to write up a thorough plan. I’ll pick this apart personally, but I also ask the LLM to pick this apart. And generally, this is where I’d switch to another context or llm model. Maybe even round robin a couple of them to further refine the plan and overall idea.
Once I feel like the plan looks good, I just let an agent rip. I tell them to pass of work to sub-agents if possible. I usually allow all edits at this point, but I keep an eye on things. Once the LLM tells me it’s done, I’ll deploy or run things locally. Take it for a spin.
Even if everything looks okay at this point, I start spinning up more agents and I start to make them more adversarial. Their goals are to find code smells, bad design, duplicate/dead code, etc. Typically one of the agents only purpose is to write tests and again, I’ll start another agent to review the tests. For the reviews on tests, it’s always important to tell them to be on the lookout for low value tests, testing of getters/setters/mocks. I want high value tests, not just tests that increase coverage and fix failures by hiding problems. I always tell them to also make sure we’re not only testing the happy path but all possible error paths as well.
This is around the time that I’ll start finding problems. I feel like at this point is where I’m going to use the LLM the most. There’s a lot of fixes to patterns here. The LLMs like to write bad code to thread the needle, at least, that’s how my general workflow goes. But then once there’s something functional I do many rounds of these reviews, fixes, testing. Sometimes there’s some regression, but the LLM is happy to fix those too.
When I see the codebase is really starting to take shape, patterns are forming, I’ll start getting things into a “finished” state and ready for release. Maybe spruce up ci/cd. Maybe create some type of e2e smoketest. And I’ll do some more manual reviews: deploy the app, install things locally in a dev/debug mode, and run through most of the functionality.
I then had the LLM walk me through distributing this as a Google Chrome plugin.
I think it only took me an hour or two to think of this idea, build it, deploy it, distribute it.
Where does it go from here
I’ll continue to fiddle with this. I still need to release it as a firefox plugin. I think I’ll make a flutter app with some extra functionality (What are the best dishes nearby?) at some point.
Hopefully people will use this so I can be better informed about what dish to get at any restaurant I visit.